xpath的使用
XPath是xml的路径语言,也是一门在xml文档中查找信息的语言。
| 表达式 | 描述 |
|---|---|
| nodename | 选取此节点的所有节点 |
| / | 从当前节点选取子节点(从根节点开始定位) |
| // | 从当前节点选取子孙节点 |
| . | 选取当前节点 |
| .. | 选取当前节点的父节点 |
| @ | 选取属性 |
| text() | 选取文本,/text()选取标签中直系的文本内容,//text()选取标签中所有文本内容。 |
(一)、举个例子
<body> <div class="container logo-search"> <div class="col search row-search-mobile"> <form action="index.php"> <input class="placeholder" placeholder="搜索……" name="s" autocomplete="off"> </form> </div> <div class="row"> <div class="col logo"> <h1><a href="/">学的不仅是技术,更是梦想!</a></h1> </div> <div class="col search search-desktop last"> <div class="search-input" > <form action="//www.runoob.com/" target="_blank"> <input class="placeholder" id="s" name="s" placeholder="搜索……" autocomplete="off" style="height: 44px;"> </form> </div> </div> </div> </div> </body> 以上代码树状图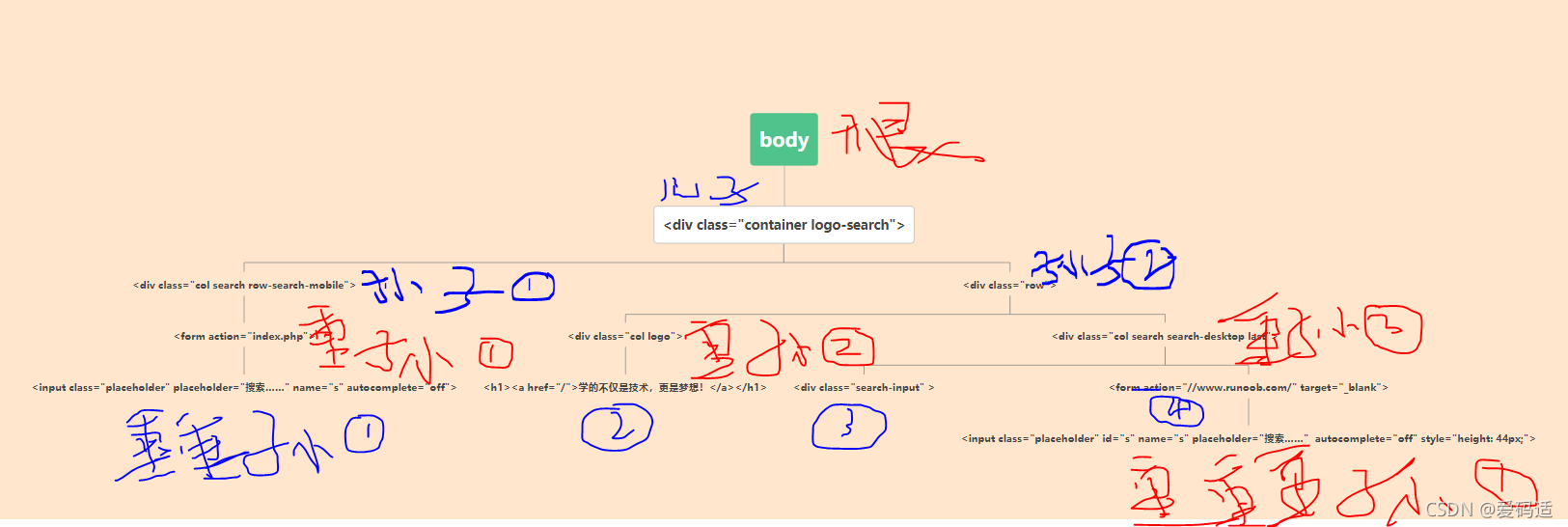
1.lxml.xpath('body'):表示选取body下面的所有子节点。
2.lxml.xpath('/body'):表示从根节点开始选取body
3.lxml.xpath('body/div'):表示选取body下面含有div的所有子节点。(只能选取儿子,孙子不能选取)
4.lxml.xpath('body//div'):表示选取body下面含有div的所有节点。(只要含有div节点,儿子,孙子,重孙都可以选取)
5.lxml.xpath('//div'):选取所有body元素(不管是重孙,孙子,儿子只要含有div都可以选取,位置不限)
6.lxml.xpath('//@placeholder'):选取名为placeholder的所有属性。
谓语用来查找某个特定的节点或者包含某个特定值的节点,谓语用“[]”括起来。
实例
| 表达式 | 描述 |
| /div/p[n] | 选取div子元素的第n个p元素 |
| /div/p[last()] | 选取div子元素的最后一个p元素 |
| /div/p[last()-1] | 选取div子元素的倒数第二个p元素 |
| /div/p[book<n] | 选取div子元素的前n-1个book元素 |
| //div/[@binbin] | 选取所有名称为binbin的div元素 |
| //div[@binbin='ch' | 选取所有div元素,且这些元素的值为ch的binbin属性 |
通配符用来选取未知节点
| 通配符 | 描述 |
| * | 匹配任何元素的节点 |
| @* | 匹配任何属性的节点 |
| node | 匹配任何类型的节点 |
实例
| 路径表达式 | 结果 |
| //div/* | 选取div下的所有子元素 |
| //div[@*] | 选取带有属性的div元素 |
HTML属性知识补充:
属性总是以名称/值的形式出现,比如:name='binbin',属性值用双引号括起来。
属性总是在HTML元素的开始标签中规定。
HTML元素的属性
| 属性 | 值 | 描述 |
| class | classname | 规定元素的类名(classname) |
| id | id | 规定元素的唯一 id |
| style | style_definition | 规定元素的行内样式 |
| title | text | 规定元素的额外信息 |
| 属性的获取 | 属性匹配 | |
| 获取a节点的href属性 | 路径表达式/a/@href | |
| 获取a节点的文本 | 路径表达式/a/[@class="thumbnail"] |
获取a节点的href属性
import requests from lxml import etree url="http://www.kmlvyouw.com/lvyoujingdian/index.html" headers={"User-Agent": 放自己的"} response=requests.get(url, headers=headers) # 返回一个经过解码的字符串,response.text返回一个文本数据。 text=response.text # text=response.content html=etree.HTML(text) # 调用etree模块的HTML类,对response进行初始化,这样成功构造xpath解析对象。 result=html.xpath('*//div//a/@href') # 对html进行解析 for i in result: a=i.encode('iso-8859-1').decode('utf-8') # 服务器默认的编码是'iso-8859-1' print(a)
属性多值匹配
有时候,某些节点的某个属性可能有多个值,例如:
from lxml import etree text=''' <li class="li li-first"><a href="link.html">first item<a/></li>''' html=etree.HTML('text') result=html.xpath('//li[class="li li-first"]/a/text()') print(result) 这里的html文本中li节点的class属性有两个值li和li-first,此时想用之前的属性匹配获取就无法获取,,此时的运行的结果如下:
[]
这时就需要用contains()函数了,代码可以改下如下:
from lxml import etree text=''' <li class="li li-first"><a href="link.html">first item<a/></li> ''' html=etree.HTML(text) result=html.xpath('//li[contains(@class,"li-first")]/a/text()') print(result)通过contains方法,第一个参数传入属性名称(@属性名称),第二个参数传入属性值(属性值任意一个就可以)。运行结果如下:
['first item']
多属性匹配
如果一个属性需要多个属性来确定,那就需要匹配多个属性。此时用and来来连接就行。代码如下
from lxml import etree text=''' <li class="li li-first" name="item"><a href="link.html">first item</a></li> ''' html=etree.HTML(text) result=html.xpath('//li[contains(@class,"li-first")and @name="item"]/a/text()') print(result)运行结果如下:
['first item']